

티스토리 뷰

[ 밑줄/연결 ]
(데이터 과학 진행 과정)

(1. 데이터 획득)
ㅇ 어떤 데이터가 필요하며 그것을 어디서 얻을 것인지를 사명서에 명시했다.
ㅇ 사용할 데이터가 존재하는지, 품질은 어느 정도인지, 접근할 수 있는지 확인한다.
(2. 데이터 준비)
ㅇ 데이터 정제(data cleansing): 데이터 출처로부터의 거짓 데이터를 제거
ㅇ 데이터 통합(data intergration): 여러 데이터 출처로부터 얻은 정보를 조합함으로써 데이터 출처를 보충
ㅇ 데이터 변환(data transformation): 데이터를 모델에 적합한 형태로 만듦
(3. 데이터 탐색)
ㅇ 데이터를 깊이 이해하는 데 주의를 기울인다.
ㅇ 변수들의 상호작용, 데이터의 분포, 이상점의 존재에 대해 이해하려고 노력한다.
ㅇ 기술적 통계학, 시각적 기법, 단순한 모델링을 주로 사용한다.
ㅇ 탐색적 데이터 분석(Exploratory Data Analysis, EDA)라고 부르기도 한다.
(4. 데이터 모델링 또는 모델 구축)
ㅇ 모델, 도메인 지식, 데이터에 대한 통찰을 가지고 연구 과제에 대한 답을 찾는다.
ㅇ 통계학, 머신러닝, 운영과학과 같은 분야의 기법을 동원한다.
ㅇ 모델을 구축하는 과정에서는 모델로부터 변수를 선택하고, 모델을 실행하고, 모델을 진단하는 것을 반복적으로 수행한다.
(5. 발표 및 자동화)
ㅇ 어떤 데이터가 필요하며 그것을 어디서 얻을 것인지를 사
(빅 데이터 생태계의 구성 요소와 기술)

(분산 파일 시스템)
ㅇ 동시에 여러 서버에서 동작한다는 특징
ㅇ 파일의 저장, 읽기, 삭제, 보안 등은 모든 파일 시스템의 핵심
ㅇ 주요한 장점은
- 한 대의 컴퓨터 디스크 용량보다 더 큰 파일을 저장할 수 있다.
- 중복 또는 병렬 운영을 위해 파일이 여러 서버에 자동으로 복제되며, 사용자는 그와 관련한 복잡성에 신경을 쓰지 않아도 된다.
- 시스템의 규모를 쉽게 변경할 수 있어서 단일 서버의 메모리나 스토리지의 제약에 얽매이지 않는다.
ㅇ 더 많은 메모리와 저장장치, 더 빠른 CPU를 가진 서버로 옮기는 식으로 처리 규모를 늘림(수직 확장)
ㅇ 작은 서버를 여러 대 추가해 규모를 키움(수평 확장) --> 가상적으로 무제한으로 확장할 수 있는 잠재력을 지님
ㅇ 가장 잘 알려진 분산 파일 시스템은 하둡 파일 시스템 (Hadoop File System, HDFS)
(분산 프로그래밍 프레임워크)
ㅇ 작업할 때 데이터를 프로그램 쪽으로 이동하는 것이 아니라, 프로그램을 데이터로 이동한다.
ㅇ 분산된 데이터를 가지고 작업할 때와 그에 수반되는 많은 도전을 다루기 편하게 오픈소스 제공
(데이터 통합 프레임워크)
ㅇ 데이터를 한 곳에서 다른 곳으로 이동하려고 할 때 Apache Sqoop(스쿠프)나 Apache Flume(플럼)과 같은 데이터 통합 프레임워크를 사용한다.
ㅇ 과정은 전통적인 데이터웨어하우스의 추출, 변환, 적재 과정과 유사하다. (ETL)
(머신러닝 프레임워크)
ㅇ 머신러닝, 통계학, 응용 수학 분야에 의존하여 통찰을 얻을 시간이다.
ㅇ 데이터 분량이 많아서 대량 데이터를 다루는 데 특화된 프레임워크와 라이브러리가 필요하다.
ㅇ 파이썬에서 가장 유명한 머신러닝 라이브러리는 사이킷런(Scikit-learn), 자연어 처리 도구, 텐서플러 등
(NoSQL 데이터베이스)
ㅇ 거대한 데이터를 저장했다면 그러한 데이터를 관리하고 질의하는 데 특화된 SW가 필요하다.
ㅇ 전통적으로 Oracle SQL, MySQL, Sybase SQL과 같은 관계형 데이터베이스의 영역
ㅇ 전통적인 데이터베이스의 저장 능력 또는 처리 능력으로는 단일 노드 이상으로 확장할 수 없고, 데이터의 스트리밍, 그래프, 비구조적 형태를 다룰 방법이 없다.
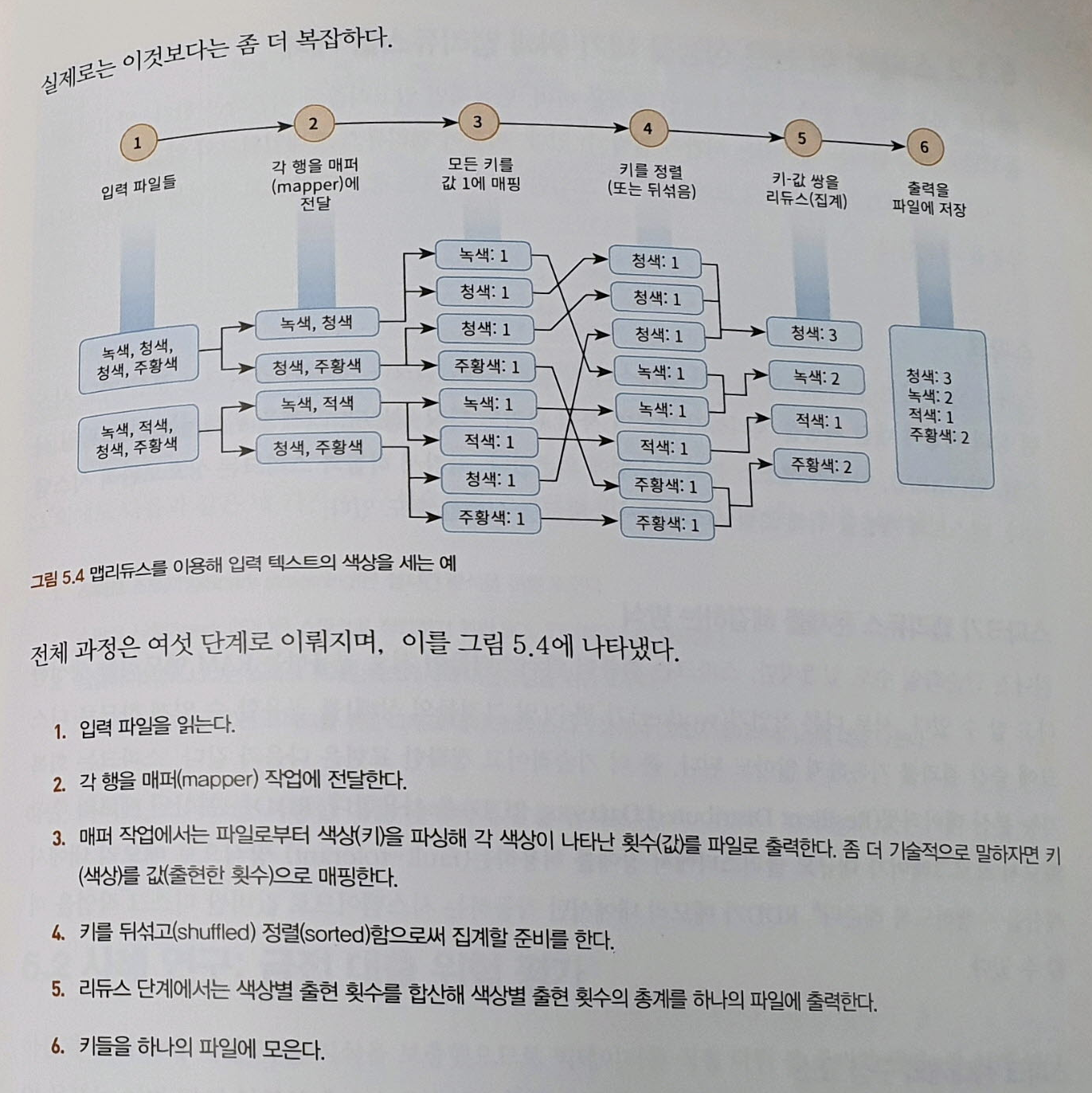
(맵리듀스: 하둡의 병렬성 구현)
ㅇ 데이터를 나누고 병렬로 처리한 다음 정렬하고 조합해 결과를 집계한다.

(스파크: 더 높은 성능을 내기 위해 맵리듀스를 대체)
ㅇ 중요도 순으로 작업을 처리함으로써 성능을 개선한다.
ㅇ 맵리듀스와 유사한 클러스터 컴퓨팅 프레임워크다. 하지만 스파크는 분산 파일 시스템 상의 파일에 대한 저장을 하지 않으며 자원 관리도 하지 않는다. HDFS, 얀(YARN), 아파치 메소드 등의 시스템에 의존한다.
ㅇ 컴퓨터 클러스터들이 서로 공유하는 RAM 메모리를 생산한다.
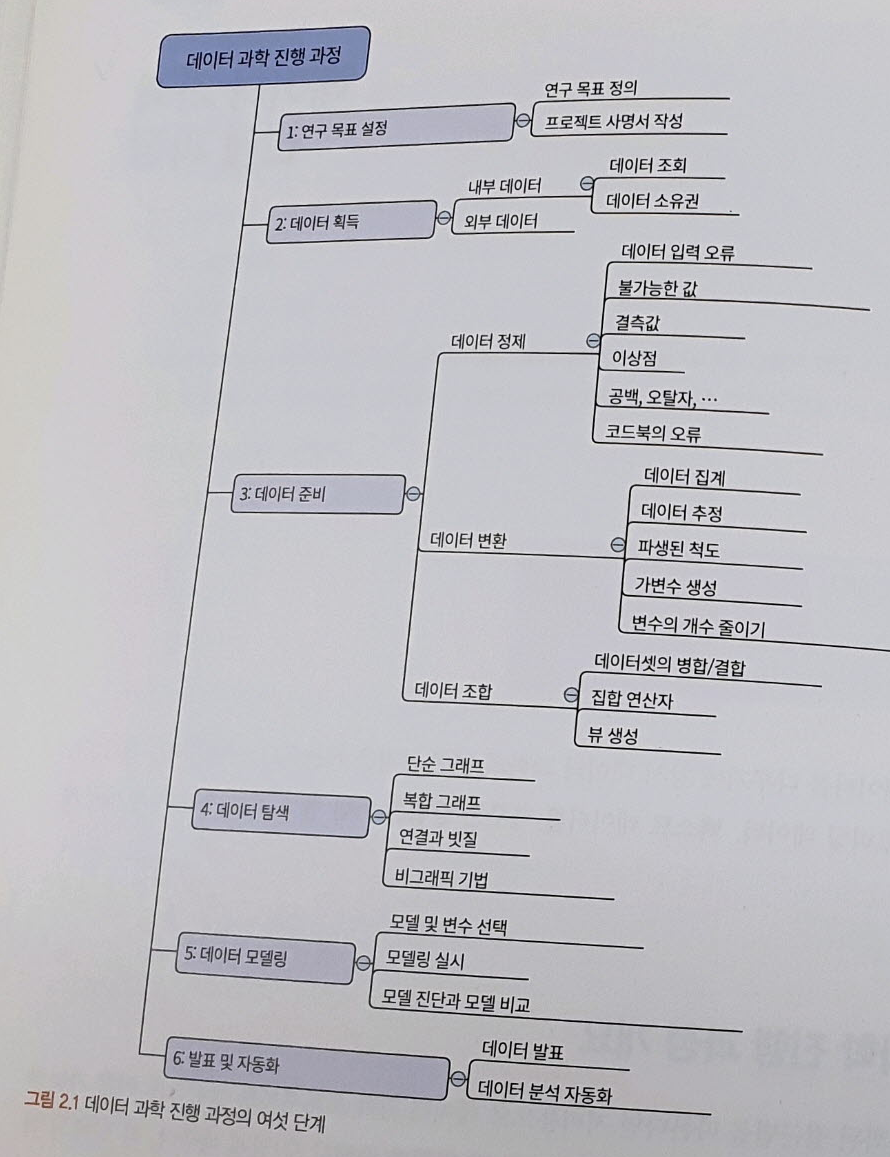
(1. 연구 목표 설정)
ㅇ 모든 이해당사자들에게 프로젝트에 대해 무엇을, 어떻게, 왜 하는지 이해시키는 것이다.
(2. 데이터 획득)
ㅇ 분석할 적당한 데이터를 찾아내서 데이터에 접근하는 과정
ㅇ 날 것(raw) 상태인 데이터를 얻게 되며, 사용하기 위해서는 가공을 해야 한다.
(3. 데이터 준비)
ㅇ 데이터에 섞여 있는 여러 가지 오류를 찾아서 수정하고, 여러 출처에서 얻은 데이터를 조합하고 형태를 바꾼다.
(4. 데이터 탐색)
ㅇ 목표는 데이터를 깊이 이해하는 것이다.
ㅇ 시각적 및 기술적 기법에 근거해 패턴, 관련성, 편차를 찾는다.

(5. 데이터 모델링)
ㅇ 통찰을 얻거나 예측하려고 시도한다.
(6. 발표 및 자동화)
ㅇ 필요하다면 분석을 자동화하는 것
ㅇ 목표는 업무 과정을 바꾸고 더 나은 의사결정을 끌어내는 것이다.
[ 자평 ]
전반적으로 빠르게 훑어 보기에는 초급자 용도로 괜찮은 듯하다.
도움을 받았다.
'IT' 카테고리의 다른 글
| 기계 학습을 다시 묻다 by 레슬리 밸리언트 (0) | 2022.01.09 |
|---|---|
| 개발 함정을 탈출하라 by 멜리사 페리 (0) | 2021.10.01 |
| 개발자에서 아키텍트로 by 마이클 킬링 (0) | 2021.08.11 |
| 플랫폼 레볼루션 by 마셜 밴 앨스타인 (Marshall W. Van Alstyne) (0) | 2021.08.03 |
| 비트의 세계 by 데이비드 아우어바흐 (0) | 2021.07.24 |
- Total
- Today
- Yesterday
- 프레임워크
- 지식론
- 돈
- 파괴적 혁신
- 상대성이론
- 안나 카레니나
- 참을 수 없는 존재의 가벼움
- 부정성 편향
- 개념
- 샤룩 칸
- 사고의 본질
- 혁신
- 불교
- 형식 지정 기법
- 양자역학
- MECE
- 게티어
- 고도를 기다리며
- Ai
- 게티어 문제
- 후감각
- 이노베이션
- 인식론
- 지식의 구조화
- 경영혁신
- 사회물리학
- 인공지능
- 생각
- 최진석
- 지식의 정의
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |