

티스토리 뷰

[ 밑줄/연결 ]
빅데이터의 취급이 어려운 이유는
(1) 데이터의 분석 방법을 모른다는 점
(2) 데이터 처리에 수고와 시간이 걸린다는 점
Hadoop: 다수의 컴퓨터에서 대량의 데이터를 처리하기 위한 시스템.
NoSQL: 빈번한 읽기/쓰기 및 분산 처리가 강점
Spark: 새로운 분산 시스템 프레임워크. MapReduce보다 효율적으로 데이터 처리를 할 수 있음. 실시간 데이터 처리를 위한 시스템도 다수 만들어 지고 있음
(데이터 파이프라인) : 데이터 수집에서 workflow 관리까지
(데이터 수집): bulk형과 streaming형의 데이터 전송
여러 장소에서 발생하고 각각 다른 형태를 보임.
전송 방식에는 크게 두 가지
ㅇ 벌크형: 이미 어딘가에 존재하는 데이터를 정리해 추출. DB나 서버 등에서 정기적으로 수집
ㅇ 스트리밍: 차례차례로 생성되는 데이터를 끊임없이 계속해서 보내는 방법. Mobile Appl. 또는 embedded 장비

스트림 처리와 배치 처리
DW에서 다루는 데이터는 주로 벌크형 방법 이용.
스트리밍 방법은 데이터를 실시간으로 처리. 예를 들면 시계열 데이터 베이스
분산 스토리지: 객체 스토리지, NoSQL DB
대량의 데이터를 저장하고 처리하는 데 적합한 분산 시스템.
어느 정도 정리된 데이터를 효율적으로 가공하기 위핸 '배치 처리' 구조
분산 스토리지: 여러 컴퓨터와 디스크로부터 구성된 스토리지 시스템.
객체 스토리지: 한 덩어리로 모인 데이터에 이름을 부여해서 파이로 저장함. amazon S3
(Data Warehouse와 Data Mart): 데이터 파이프라인의 기본형
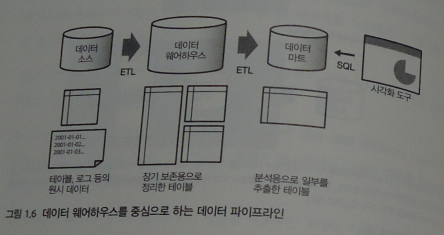
DW는 웹 서버나 업무 시스템에서 이용하는 일반적인 RDB와는 달리 '대량의 데이터를 장기 보존'하는 것에 최적화되어 있음. 정리된 데이터를 한 번에 전송하는 것은 뛰어나지만, 소량의 데이터를 자주 쓰고 읽는 데는 적합하지 않음. 전형적인 사용 방법으로는 업무 시스템서 꺼낸 데이터를 하루가 끝날 때 정리하여 쓰고, 이것을 야간 시간대에 집계해서 보고서를 작성한다.
'Data Source'(업무 시스템을 위한 RDB나 로그 등을 저장하는 파일서버) --> raw data 추출하고 필요에 따라 가공 후 DW에 저장하기까지의 흐름이 'ETL Process'다. DW구축에는 'ETL 도구'라는 전용 SW가 자주 이용됨. DW를 중심으로 하는 파이프라인에서는 데이블 설계와 ETL 프로세스가 중요함.
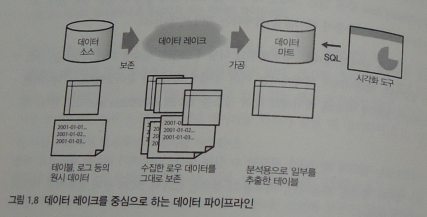
(Data Lake) : 데이터를 그대로 축적
모든 데이터를 원래의 형태로 축적해 두고 나중에 그것을 필요에 따라 가공하는 구조가 필요
임의의 데이터를 저장할 수 있는 분산 스토리지를 이용
데이터 형식은 자유롭지만 대부분의 경우는 CSV나 JSON 등의 범용적인 text 형식이 사용됨
데이터 레이크는 단순히 스토리지이며, 그것만으로는 데이터를 가공할 수 없음
MapReduce 등의 분산 데이터 처리 기술이 필요. 데이터를 가공, 집계, 이를 data mart로 추출한 후에 분석 진행

(데이터를 수집하는 목적) : 검색, 가공, 시각화

기간계 시스템(mission-critical system)
ㅇ 비즈니스 근간에 관련된 중요한 시스템으로 정지되면 업무가 멈추기 때문에 완벽하게 테스트하고 반복하고 신중하게 운영해야 함
정보계 시스템(information system)
ㅇ 사내 커뮤니케이션과 의사 결정 등을 위해 이용하는 시스템으로, 정지되어도 그 영향 범위가 제한적
데이터란 기간계 시스템과 정보계 시스템을 연결하는 것. 기간계 시스템은 그 실행 과정을 로그 파일이나 DB 등에 기록함. 정보계 시스템은 데이터를 복사하는 데서 부터 시작함. Data 복사 없이는 정보계 시스템이 기간계 시스템에 연결되지 못함. ...데이터 분석 시스템은 원칙적으로 정보계 시스템으로 취급함.

BI도구는 고속의 집계 엔진을 내장하고 있어 수백만 레코드 정보의 스몰 데이터라면 순식간에 그래프를 그려줌. ad-hoc 분석 등에서 대화형으로 데이터를 시각화하고 싶을 때 특히 편리함
처음부터 입맛에 맞게 정리된 데이터가 있는 경우는 거의 없음. 제대로 설계된 데이터가 없다면, 자신의 생각과 딱 맞는 화면을 만들 수 없다는 점이 BI 도구의 한계

(분산 데이터 처리 및 쿼리 엔진) MapReduce, Hive
SQL 등의 쿼리 엔진에 의한 Data 집계가 목적이라면 그것을 위해 설계된 쿼리 엔진을 사용함. Hive는 그런 쿼리 엔진 중 하나이며, 퀴리를 자동으로 MapReduce 프로그램으로 변환하는 SW로 개발되었음.
(Spark) 인 메모리 향의 고속 데이터 처리
컴퓨터에서 취급하는 메모리의 양이 증가함에 따라, 뭐든지 디스크에서 읽고 쓰는 것이 아니라 '가능한 한 많은 데이터를 메모리상에 올린 상태로 두어 디스크에는 아무것도 기록하지 않는다'는 선택이 현실화되었다.
Spark는 Hadoop을 대체하는 것이 아니라 MapReduce를 대체하는 존재다. 예를 들어, 분산 파일 시스템인 HDFS나 리소스 관리자인 YARN 등은 Spark에서도 그대로 사용할 수 있다. Hadoop을 이용하지 않는 구성도 가능하며, 분산 스토리지로 amazon s3를 이용하거나 분산 DB인 카산드라에서 데이터를 읽어 들이는 것도 가능하다.
Spark의 실행은 자바 런타임이 필요하지만, Spark상에서 실행되는 데이터 처리는 스크립트 언어를 사용할 수 있다는 점도 매력...표준으로 자바, 스칼라, 파이썬, R.....

(퀴리 엔진)
데이터 마트 구축의 파이프라인
Hadoop에 의한 구조화 데이터 작성과 이를 이용한 쿼리의 실행...
Hive와 Presto를 결합한 데이터 파이프라인

(열 지향 스토리지에 의한 고속화)
메모리에 다 올라가지 않을 정도의 대량의 데이터를 신속하게 집계하려면, 미리 테이블을 집계해 적합한 형태로 변환하는 것이 필요함. 집계 효율을 높이는 DB 구조의 기술 중 하나..
(열 지향 DB 접근): 칼럼을 압축하여 디스크 I/O를 줄이기
일반적으로 업무 시스템 등에서 사용되는 DB는 레코드 단위의 읽고 쓰기에 최적화되어 있으며, 이를 '행 지향 DB'라고 부름. 예를 들면 Oracle, MS SQL 등....대부분의 RDB는 모두 행 지향 DB임
이에 반해 데이터 분석에 사용되는 DB는 칼럼 단위의 집계에 최적화되어 있으며, 열 지향 DB 또는 칼럼 지향 DB라고 함. Teradata와 Amazon Redshift 등이 열 지향 DB임
(열 지향 DB) 칼럼마다 data를 모아 두기
데이터 분석에는 종종 칼럼만이 집계 대상이 됨. 예를 들어, 점포의 총매출액을 알고 싶을 때는 고객 정보는 필요 없음. 행 지향 DB는 레코드 단위로 데이터가 저장되어 필요 없는 열까지 디스크로부터 로드됨.
열 지향 DB에서는 데이터를 미리 컬럼 단위로 정리해 둠으로써 필요한 컬럼만을 load하여 디스크 I/O를 줄임

[ 자평 ]
빅 데이터 기술에 대한 기본적인 사항을 쉽게 잘 썼다.
'IT' 카테고리의 다른 글
| 정보적 사고에서 인공 지능까지 by 김현철 (0) | 2021.05.16 |
|---|---|
| 만물 해독 by 찰스 세이프 (0) | 2021.05.10 |
| 인문학도, 개발자 되다 by 마르코 (0) | 2021.01.17 |
| 정보와 사회 by 마이클 버클랜드 (0) | 2021.01.17 |
| SW가 세상을 지배한다 by 김재호 (0) | 2020.12.31 |
- Total
- Today
- Yesterday
- 참을 수 없는 존재의 가벼움
- 안나 카레니나
- 혁신
- 직감하는 양자역학
- 최진석
- 전략에 전략을 더하라
- 이노베이션
- 사회물리학
- 플랫폼의 시대
- 상대성이론
- 경계의 종말
- 스케일의 법칙
- 부정성 편향
- 데브옵스 도입 전략
- 함께 있으면 피곤한 사람
- 경영혁신
- 불교
- 당신은 AI를 개발하게 된다
- 고도를 기다리며
- 개발자가 아니더라도
- 파괴적 혁신
- 함께 있으면 즐거운 사람
- 개발자에서 아키텍트로
- 인공지능
- 복잡계의 새로운 접근
- 양자역학
- 디지털 트랜스포메이션 엔진
- 제로 성장 시대가 온다
- 돈
- Ai
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |