

티스토리 뷰

[ 밑줄/연결 ]
생성 AI는 학습된 패턴과 규칙을 기반으로 이미지, 음악, 텍스트 등 새로운 콘텐츠를 생성할 수 있는 AI 모델을 말하는데, 생성 AI 모델은 종종 신경망과 같은 딥 러닝 기술을 기반으로 하여 데이터의 패턴과 구조를 학습하기 위해 대규모 데이터에서 트레이닝 되다.
챗GPT는 생성 모델이지만 기본적으로 언어의 기본 또는 스크립트인 텍스트가 생성된다. 언어 모델은 문장이나 어구에서 선행 단어가 주어지면 단어가 발생할 가능성을 예측하는 데 사용되는 확률 모델이다.
챗GPT는 우리 모든 일상에서 범용적으로 쓸 수 있는 AI라는 점에서 기존 AI와 다르다.

챗GPT와 같은 LLM기술의 가장 큰 단점ㅇ 근거가 모호한 '아무말 대잔치'ㅇ 비용이 어마어마하게 든다. 검색보다 100배 비용, RIO BM 이슈ㅇ 저작권 문제 : 데이터 크롤링 통해 학습하는 과정에서 허락받지 않은 데이터를 쓸 수 있다.
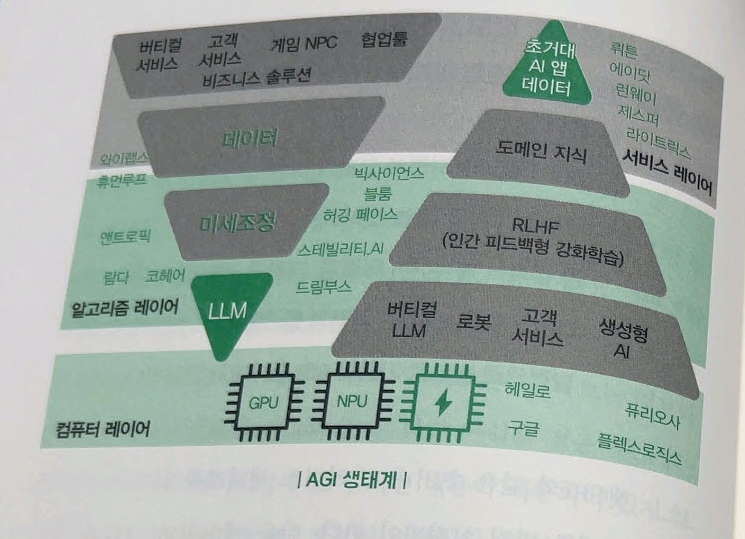
(컴퓨터 레이어)
ㅇ 챗GPT와 같은 서비스를 가동하기 위해서는 LLM이 필요한데, 이 LLM이 가동하려면 어머어마한 컴퓨터 자원이 있어야 한다
ㅇ GPU, NPU 또 메모리 반도체 + 클라우드
ㅇ NVDIA GPU, 구글 NPU 등
ㅇ LLM이 API를 호출해 다양한 컴퓨터 인프라를 끌어다 쓸 수 있도록 도와주는 클라우드 지원 사업자: 구글, MS(GPT 3.5, GPT 4 등) , 네이버(하이퍼클로사 스튜디어 통해서 한국형 LLM API 제공)
(LLM)
ㅇ SOTA LLM (State of art, 최첨단 수준) LLM
ㅇ 감히 넘볼 수 없는 최고 절정의 AI로 소수 기업만이 만들 수 있음
ㅇ 클라우드 기반의 API를 호출하거나, LLM API를 호출하여 가져다 쓸 수 있다.
ㅇ SOTA LLM을 가지고 있는 대표적 기업: 오픈 AI, 스테빌리티 AI, 허깅스페이스,앤트로픽 등, 구글(람다, 팜), 네이버(하이퍼클로바, 카카오(KoGPT), 아마존(타이탄), 메타(람마, 샘) 등
ㅇ LLM은 언어를 따지지 않는다. LLM입장에서는 영어, 한국어, 일본어를 가리지 않고 모든 인간의 언어를 0과 1비트로 이해한다. 영어인지, 한국어인지는 중요하지 않다. 각 국가에 있는 개별 로컬 LLM은 의미가 없다.
ㅇ 단 각 산업 영역별, 도메인별로 버티컬 LLM의 필요성은 제기될 수 있다. 그런 LLM을 기업에서 잘 활용할 수 있도록 파인튜닝, 데이터 그라운딩 등을 하는 솔루션 비즈니스 기회도 있을 것
(애플리케이션)
ㅇ 카카오톡, 페이스북, 인스타그램 등이 모바일에서 승자인 것처럼 AGI시장에서 결국 생성 AI를 활용해 서비스를 만드는 기업이 승자가 될 것이라는 관점
ㅇ SOTA LLM을 가져다 AGI 서비스로 부가가치를 최대한 극대화해서 만들면 된다.
ㅇ AI 콘텐츠 생성 플랫폼 '뤼튼', 미국의 Jesper, 동영상 편집/생성 서비스 '런웨이', 오디오 LM, 달리 등
(LLM이 실제 서비스에 사용되기 위해서는 4가지 과정이 필요)
(1) GPU와 함께 구축한 컴퓨터 인프라
(2) LLM을 클라우드에 연동
(3) LLM을 더욱 커스터마이징해서 사용하기 위해 특정 데이터를 넣어(그라운딩) 파인튜닝하는 것
(4) 파인튜닝한 LLM을 활용해 생성AI를 만들거나 기존 서비스에 적용하는 것
LLM을 만들기 위해서는 돈과 기술력, 딱 2가지가 필요하다.
파인튜닝과 그 안에 들어가는 그라운딩 데이터를 집어넣고 조정하는 일
MS는 엣지에 확장 프로그램을 넣고 다양한 외부의 LLM API를 기반으로 만들어진 생성 AI를 제공할 것이다.
앞으로는 생성 AI 생태계에서 엣지 브라우저와 챗GPT가 그동안 웹의 관문 역할을 한 포털이나 검색 엔진처럼 구심점이 될 수도 있을 것이다.
챗GPT나 MS 엣지 브라우저에서 AGI 서비스들을 한데 묶어 새로운 슈퍼앱이 탄생한다면 이는 기존의 구글이나 네이버, 카카오, 페이스북과 같은 파워풀한 고객 접점을 갖춘 인터넷 기업들에게는 위기가 될 것이다.



마치 Private Cloud를 구축하는 것과 같이 우리 만의 버티칼 LLM이 필요하다.
"이 분야는 LLM자체가 특화되어서 깊고 좁아야 해"라는 목표라면 버티칼 LLM을 만들어야 한다.
산업 데이터를 집어넣어 데이터 못(data moat)를 만들어 파인튜닝을 고도화해서 우리 내부에 있는 비즈니스 도메인 혹은 구성원에게 쓸 수 있도록....
멀티 클라우드처럼 여러 LLM 엔진을 섞어서 활용하는.....
데이터 - LLM - 대화형 UI - 사물인터넷 이 4가지 관점으로 들여댜 봐야 한다.
챗GPT API로 신규 혹은 기존 서비스에 새로운 기능을 추가해 제공할 때는 파인튜닝을 통해 챗GPT를 구미에 맞게 파라미터값을 변경해서 서비스에 맞게 최적화해야 한다. 또한 그 과정에서 기업 고유의 데이터를 넣어 범용적인 챗GPT로는 얻기 어려운 답변을 받을 수 있도록 해야 한다.
API는 챗GPT를 밖에서 사용할 수 있는 것이라면, 플러그인은 챗GPT 홈 페이지 내에서 외부의 서비스를 호출하여 사용하는 것을 뜻한다.
SOTA LLM API를 가져다가 유료 콘텐츠를 데이터로 그라운딩해서 기본 유료 서비스를 대체할 만큼의 서비스를 제공하는 3rd Party 서비스 회사가 등장 할 수는 있다.
프롬프트 시스템 엔지니어링은 데이터와 파인튜닝을 잘하는 과정이다.
[ 자평 ] 밥법이를 위해 어쩔 수 없이 훑어 읽은 책...
이런 책들은 읽어야 할 시간이 있어 그 시절 지나면 가치가 없다. 재독도 필요 없고
'지능 > 인공지능' 카테고리의 다른 글
| 챗GPT 사용설명서 by 송준용 (0) | 2023.10.08 |
|---|---|
| 챗GPT 거부할 수 없는 미래 by 서지영 (1) | 2023.10.07 |
| 트랜스포머를 활용한 자연어 처리 by 루이스 턴스톨 외 (0) | 2023.10.02 |
| 생각을 기계가 하면, 인간은 무엇을 하나? by 존 다니허 (0) | 2023.09.03 |
| AI쇼크, 다가올 미래 by 모 가댓 (0) | 2023.07.09 |
- Total
- Today
- Yesterday
- 고도를 기다리며
- 복잡계의 새로운 접근
- 개발자가 아니더라도
- 불교
- 안나 카레니나
- 제로 성장 시대가 온다
- 경계의 종말
- 상대성이론
- 혁신
- 부정성 편향
- 개발자에서 아키텍트로
- 스케일의 법칙
- 참을 수 없는 존재의 가벼움
- 돈
- 최진석
- 함께 있으면 피곤한 사람
- 인공지능
- 파괴적 혁신
- 당신은 AI를 개발하게 된다
- 디지털 트랜스포메이션 엔진
- 이노베이션
- 함께 있으면 즐거운 사람
- 경영혁신
- 사회물리학
- 데브옵스 도입 전략
- 양자역학
- 지승도
- Ai
- 플랫폼의 시대
- 전략에 전략을 더하라
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |